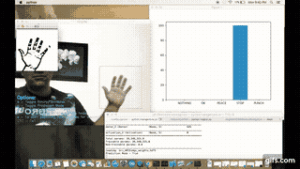
In this post let me show you, how I used Supervised Learning to teach an AI agent to play game. In my earlier post to this series – #posture recognition, I showed how to do posture recognition using a simple CNN model along with the OpenCV library. This framework utilizes the Supervised Learning approach. I am using the same project and in fact, the same CNN model with minor tweaks in the output layer to train or teach an AI agent to play a simple game itself.
AI agent Rex… TRex:
For the game, I have chosen the inbuilt game available with the Chrome browser. It’s a simple 2D game with the TRex character to jump and evade the incoming hurdles. So TRex will be our AI agent.
Now keep in mind, I am not going after a perfect solution to enable our AI agent to play forever. That would be cheating right?
What is Supervised Learning?
“Supervised learning is the machine learning task of inferring a function from labeled training data.[1] The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a “reasonable” way. — Wikipedia “
The simplest analogy I can think of is the way we are taught at school, where the teacher teaches by first asking a problem and then provides a solution to it. For eg:
- 2 + 3 = ? 5 !! or,
- What is the color of the sky? Blue!
How are we going to teach AI agent?
If you have played this game then you would already be knowing that this TRex character can be controlled with the following actions:
- Jump (Up Arrow key or Space key)
- Crouch (Down Arrow key) or
- Just Run (default action)
So all we require to teach our beloved TRex is when to jump and when not to jump (for simplicity we are ignoring Crouch action, Crouching is for noobs :p ).
And to do that, our TRex character should have following two capabilities:
– Eyes: Ability to see what we are teaching it. We could use the OpenCV library to capture the screen contents through an external camera Or directly read back the screen contents more like taking continuous screenshots. I have used the second option.
– Brain: Ability to make decisions of when to jump and when not. We would use the Convolution Neural Network for this. Images that we capture above will be fed into the Neural Network, first to train it and later for predictions. Since we have to make just two decisions of Jump or Not Jump, we will train this model for two sets of training image data.
One set of image samples will tell when to Jump
And the other set for when not to Jump.
Note: We don’t want to capture the whole screen contents but just the game area of the browser where TRex character is playing. That should be sufficient for our need and also performant.
Sample image set generation:
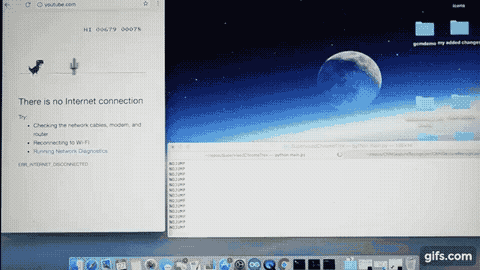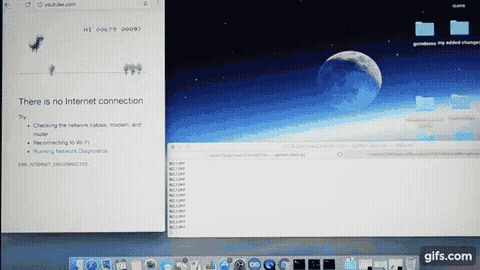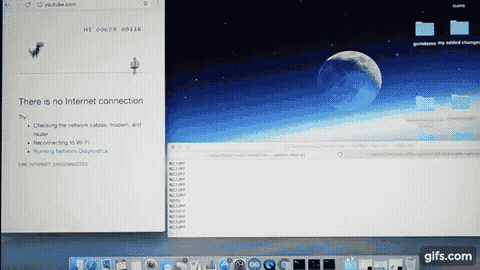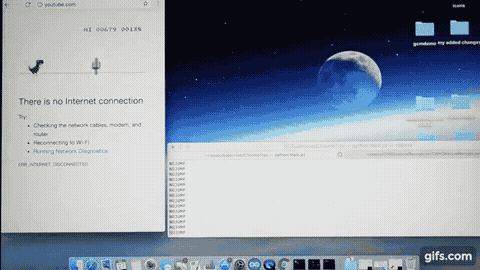
Now let’s generate our training image sample data. For this, I would suggest you to play the game yourself, if you have not played it before. Just open a Chrome browser, disconnect the Internet and try to open any website. You should see the “There is no internet connection” message. Just press the Up Arrow key to initiate the game.
Carefully monitor when you are pressing the Up Arrow key to jump. You should easily notice that as soon as any obstacle comes near to TRex, up-to a certain distance, you make TRex to jump over the obstacle. You don’t want to jump too early or too late. This also means that we are only concerned about that small region around TRex which extends till this ‘certain distance’ on the right of TRex and we will capture image contents of this region instead of complete-game region for better efficiency due to less image processing involved.
In the project, I have added below logic to create and save the training image samples
if I press Up Arrow key:
Save the screen contents as Jump sample image
else:
Save the screen contents as No Jump sample imageTraining sample sets:
And here are my training image samples. I have divided them into two sets:
- When to make the ‘jump’ decision
- When Not to make the ‘jump’ decision
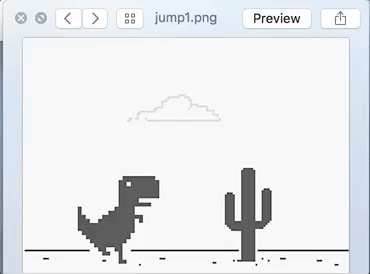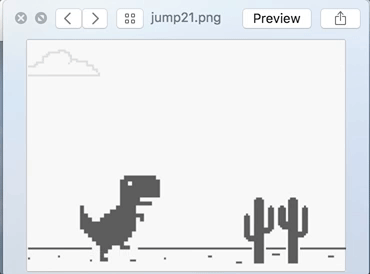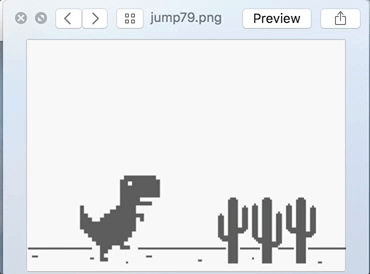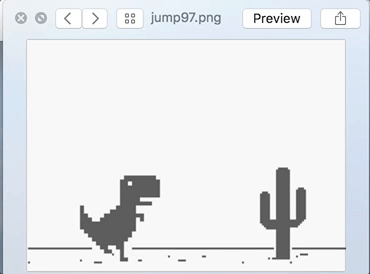
Jump sample set :
No Jump sample set:

But both the training sets look same. Why ?
Well, on the first look, they do look the same. But look closely and you would notice the difference in the distance of the incoming cactus plants from the TRex character. In the Jump set, the distance is lesser than the No Jump set. In other words, I am simply teaching the TRex at which distance it should make the jump.
Once I trained the model using the above image samples, I used the trained model to do the predictions on a live game execution. By the way, the prediction outputs (Jump or No Jump) are passed to the Chrome browser i.e Up Arrow Key (Jump) & no input (for No Jump) to control TRex.
And this is how it turned out.
This is still not perfect for instance, as you progress the TRex velocity increases and this also impacts the instance you need to make it jump. Current image samples don’t handle this scenario. But like I said before, I am not going after a perfect model, maybe later. Perhaps if you are interested then you can perfect it, will be good exercise.
Here is the source code for this project:
https://github.com/asingh33/SupervisedChromeTrex
Please provide your feedback for this series, if it was of any help to you. Would love to hear, if you made use of it in your own way. For the next post, I am want to implement the same project using the Reinforcement Learning method which is an Unsupervised method of learning or may be on my own created game.